种一颗树的最好时机是十年前,其次是现在。
学习也一样。
跟着霍老师的《深入理解 Kotlin 携程》学习一下协程。
一点前言
随着RxJava的流行,响应式编程模型逐步深入人心。Flow就是kotlin协程与响应式编程模型结合的产物。
认识Flow
我们从序列生成器开始
1
2
3
4
5
| val ints = sequence {
(10..30).forEach {
yield(it)
}
}
|
这里如果希望在元素之间加个延时怎么办?因为受restrictsSuspension注解的约束,delay函数不能再SequenceScope的扩展成员中被调用
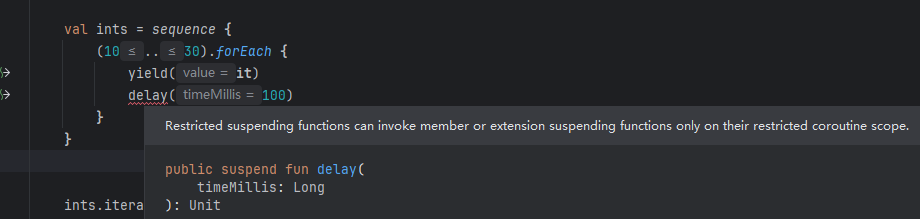
假设序列生成器不受这个限制,调用delay函数会导致后续的执行流程的线程发生变化,外部的调用者发现在访问ints的下一个元素的时候居然还会有切换线程的副作用。不仅如此,通过制定调度器来限定序列创建所在的线程同样是不可以的,我们甚至没有办法为它设置协程上下文。
那么我们来看一下Flow。
1
2
3
4
5
6
| val intFlow = flow {
(1..3).forEach {
emit(it)
delay(1000)
}
}
|
Flow也可以设定它运行时所使用的调度器:
1
| intFlow.flowOn(Dispatchers.IO).collect { println(it) }
|
最终消费intFlow需要调用collect函数。
冷数据流
在Flow创建出来之后,不消费则不生产,多次消费则多次生产,生产和消费总是相对应的。
1
2
3
4
5
6
7
8
9
10
| suspend fun main() {
val intFlow = flow {
(1..3).forEach {
emit(it)
delay(1000)
}
}
intFlow.flowOn(Dispatchers.IO).collect { println(it) }
intFlow.flowOn(Dispatchers.IO).collect { println(it) }
}
|
这里会输出两次“123”
异常处理
Flow的异常处理也比较直接,直接调用catch函数即可。需要注意的是,catch函数只能捕获它上游的异常,并且,当我们没有调用catch函数时,未捕获的异常会在消费时抛出。当然了,我们可以使用onCompletion来进行FLow完成时的逻辑
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| suspend fun main() {
flow {
emit(1)
throw ArithmeticException("div 0")
}.catch { t: Throwable ->
println("caught error :$t")
}.onCompletion { t: Throwable? ->
println("finally.")
}.flowOn(Dispatchers.Default)
.collect { value -> println(value) }
}
```
`onCompletion`类似于`try ... catch ... finally` 中的finally。这套处理机制的设计初衷是确保Flow操作中异常的透明,因此我们**不能**或者**禁止**这样写:
``` kotlin
flow {
try {
emit(1)
throw ArithmeticException("Div 0")
} catch (e: ArithmeticException) {
println("caught error: $e")
}finally {
println("finally")
}
}
|
末端操作符
collect是最基本的末端操作符,还有其他末端操作符,大体分为两类
- 集合类型转换操作符,包括toList、toSet等
- 聚合操作符,包括将Flow规约到单值的reduce、fold等操作;还有获得单个元素的操作符,包括single、singleOrNull、first等
由于Flow的消费端一定需要运行在协程中,因此末端操作符都是挂起函数。
分离Flow的消费和触发
我们还可以通过onEach来做到这一点,这样消费的具体操作就不需要与末端操作符放到一起,collect函数可以放到其他任意位置调用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| fun createFlow() = flow<Int>{
(1..10).forEach {
emit(it)
delay(1000)
}
}.onEach {
println(it)
}
suspend fun main() {
GlobalScope.launch {
createFlow().collect()
}
delay(20 * 1000)
}
|
需要注意一下,Flow并没有提供取消操作,想要取消Flow,只需要取消它所在的协程即可。
其他Flow的创建方式
当我们使用flow{...}来创建Flow时,无法随意切换调度器,因为emit函数不是线程安全的。想要在生成元素时切换调度器,就必须使用channelFlow函数来创建Flow:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| channelFlow {
send(1)
withContext(Dispatchers.IO){
send(2)
}
}
```
此外,我们可以通过集合矿建来创建Flow:
``` kotlin
suspend fun main() {
listOf(1, 2, 3, 4).asFlow().collect { value -> println(value) }
setOf(1, 2, 3, 4).asFlow().collect { value -> println(value) }
flowOf(1, 2, 3, 4).collect { value -> println(value) }
}
```
### 背压
只要是响应式编程,就一定会有背压问题,背压问题在生产者的生产速率高于消费者的处理速率情况下出现。为了保证数据不丢失,我们可以添加一个制定容量的buffer。但这只是治标不治本的方法,随着时间的推移,还是会造成时间上的积压。
出现背压问题的根本原因是生产者和消费者的速速率不匹配,除了直接优化消费者的性能外,我们还可以采取一些取舍的手段。
第一种是conflate,和Channel的Conflate模式一致,新数据覆盖老数据。
``` kotlin
suspend fun main() {
flow {
List(100){
emit(it)
}
}.conflate()
.collect{value ->
println("Collected: $value")
delay(100)
println("$value collected")
}
}
|
虽然我们发送了100个元素,但最终只接收到2个,多次运行的结果并不相同。
第二种是collectLasted,只处理最新的数据,区别在于:collectLasted并不会直接用新数据覆盖老数据,而是每一个数据都会处理,只不过如果前一个还没被处理完后一个就来了话,处理前一个数据的逻辑就会被取消。
1
2
3
4
5
6
7
8
9
10
11
| suspend fun main() {
flow {
List(10) {
emit(it)
}
}.collectLatest { value ->
println("Collected: $value")
delay(1000)
println("$value collected")
}
}
|
输出
Collected: 0
Collected: 1
Collected: 2
Collected: 3
Collected: 4
Collected: 5
Collected: 6
Collected: 7
Collected: 8
Collected: 9
9 collected
前面的println("Collected: $value")输出了所有结果,后面的println("$value collected")只输出了最后一个结果,因为后面的数据到达时,处理上个数据的操作正好被挂起了。
除此之外,还有mapLatest,flatMapLatest等。
Flow的变换
我们可以使用map来变换Flow的数据
1
2
3
4
5
6
7
8
9
10
11
| suspend fun main() {
flow {
List(5) {
emit(it)
}
}.map {
it * 2
}.collect {
println(it)
}
}
|
输出
0
2
4
6
8
还有按照顺序拼接的flattenConcat,不保证顺序的flattenMerge操作等
以上