MMKV与SharedPreference
鉴于SP的”种种问题”,萌发了想要使用写文件的方式替换掉sp的想法,发现腾讯开源MMKV是个不错的选择。
存储方式
- SharedPreferences
- ContentProvider
- 文件
- 数据库
如何选择
| 时间开销 | 这里说的时间开销包括了CPU时间和/0时间,在I/O优化中我就多次提到相比CPU和内存,I/0存储的速度是非常慢的。但是如果存储方法中比如编解码或者加密/解密等设计的比较复杂,整个数据存储过程也会出现CPU时间变得更长的情况 |
| 正确性 | 选择存储方案的时候,第一个需要判断它是否靠谱。这套存储方案设计是否完备,有没有支持多线程或者跨进程同步操作。内部是否健壮,有没有考虑异常情况下数据的校验和恢复,比如采用双写或者备份文件策略,即使主文件因为系统底层导致损坏,也可以一定程度 上恢复大部分数据 |
| 空间开销 | 即使相同的数据如果使用不同的编码方式,最后占用的存储空间也会有所不同。举一个简单的例子,相同的数据所占的空间大小是XML>JSON>ProtocolBuffer。除了编码方式的差异,在一些场景我们可能还需要引入压缩策略来进-步减少存储空间,例如zip、lzma等。数据存储的空间开销还需要考虑内存空间的占用量,整个存储过程会不会导致应用出现大量GC、OOM等 |
| 安全 | 应用中可能会有一些非常敏感的数据,即使它们存储在/data/data中,我们依然必须将它们加密。例如微信的聊天数据是存储在加密的数据库中,一些些账号相关的数据我们也要单独做加密落地。根据加密强度的不同,可以选择RSA、AES、chacha20、 TEA这些常用的加密算法 |
| 开发成本 | 有些存储方案看起来非常高大上,但是需要业务做很大改造才能接入。这里我们当然希望能无缝的接入到业务中,在整个开发过程越简单越好 |
| 兼容性 | 业务不停地向前演进,我们的存储字段或者格式有时候也会不得不有所变化。兼容性首先要考虑的是向前、向后的兼容性,老的数据在升级时能否迁移过来,新的数据在老版本能否降级使用。兼容性另外一个需要考虑的可能是多语言的问题,不同的语言是否支持转换 |
sp的N宗罪
- 跨进程不安全
- 加载缓慢:异步加载,但是异步加载线程没有设置优先级,如果这时候主线程读取数据需要等待加载线程执行完毕(也就是主线程等待低优先级线程锁的问题)
- 全量写入:无论是commit还是apply,即使改动一个条目,也会把全部内容写到文件
- 卡顿:异步落盘机制在应用崩溃时会导致数据丢失
下面是SP操作源码的简介图,来源:https://juejin.im/entry/6844903488271417351
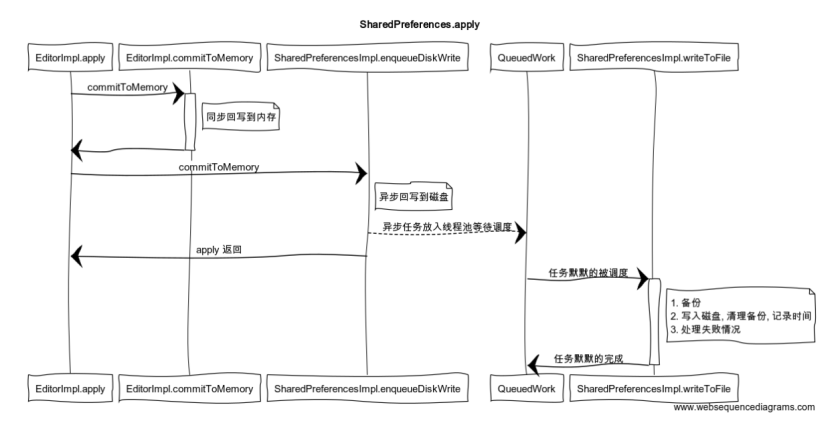
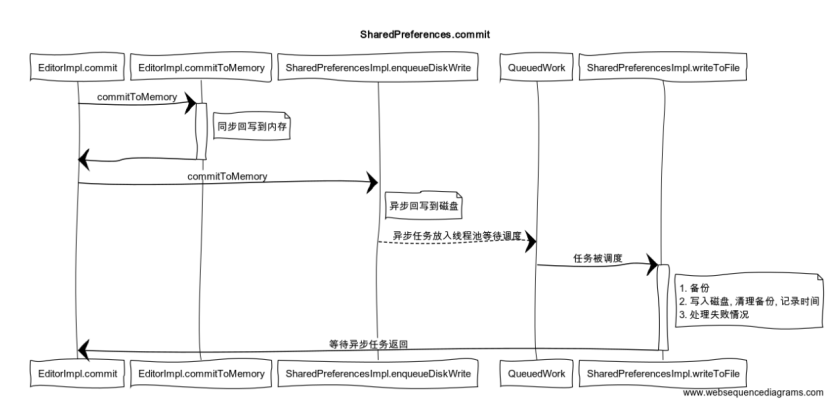
SP优化
可以在Application中重写getSharedPreference方法,返回自己实现的sp。我们可以自己将多次读写进行合并
MMKV与SP
| 关键要素 | SP | MMKV |
|---|---|---|
| 正确性 | 差 跨进程和apply机制导致数据丢失 |
优 使用mmap和文件 锁保证数据完整 |
| 时间开销 | 差 全量写入、卡顿 |
优 1.使用mmap 2.修改插入文件尾部,无需全量写入 |
| 空间开销 | 差 使用XML,格式比较冗余 |
良 使用Protocol Buffer,但是增量更新可能会导致部分冗余 |
| 安全 | 差 完全明文存储,没有支持加密与权限校验,不适合存放敏感数据 |
良 使用Protocol Buffer,不是完全明文。没有支持加密与权限校验,不适合存放敏感数据 |
| 开发成本 | 优 系统支持,非常简单 |
良 需要引入单独库,有一定的改造成本 |
| 兼容性 | 优 支持前后兼容 |
优 支持前后兼容,支持导入 SharedPreferences历史数据,但注意 转换后版本无法回退 |
MMKV原理:来源https://github.com/Tencent/MMKV
内存准备
通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
简化版
数据组织
数据序列化方面我们选用 protobuf 协议,pb 在性能和空间占用上都有不错的表现。考虑到我们要提供的是通用 kv 组件,key 可以限定是 string 字符串类型,value 则多种多样(int/bool/double 等)。要做到通用的话,考虑将 value 通过 protobuf 协议序列化成统一的内存块(buffer),然后就可以将这些 KV 对象序列化到内存中。
写入优化
标准 protobuf 不提供增量更新的能力,每次写入都必须全量写入。考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力:将增量 kv 对象序列化后,直接 append 到内存末尾;这样同一个 key 会有新旧若干份数据,最新的数据在最后;那么只需在程序启动第一次打开 mmkv 时,不断用后读入的 value 替换之前的值,就可以保证数据是最新有效的。
空间增长
使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。例如同一个 key 不断更新的话,是可能耗尽几百 M 甚至上 G 空间,而事实上整个 kv 文件就这一个 key,不到 1k 空间就存得下。这明显是不可取的。我们需要在性能和空间上做个折中:以内存 pagesize 为单位申请空间,在空间用尽之前都是 append 模式;当 append 到文件末尾时,进行文件重整、key 排重,尝试序列化保存排重结果;排重后空间还是不够用的话,将文件扩大一倍,直到空间足够。
数据有效性
考虑到文件系统、操作系统都有一定的不稳定性,我们另外增加了 crc 校验,对无效数据进行甄别。在 iOS 微信现网环境上,我们观察到有平均约 70万日次的数据校验不通过。
使用方式
https://github.com/Tencent/MMKV github上有对应的示例
参考
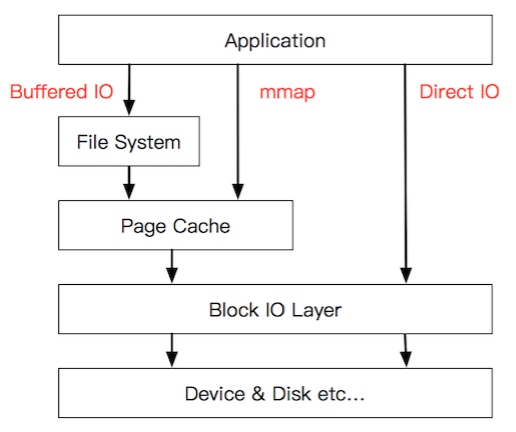
聊聊 Linux IO
磁盘I/O那些事
Linux 内核的文件 Cache 管理机制介绍
Linux 中直接 I/O 机制的介绍
MemoryFile
MappedByteBuffer
彻底搞懂 SharedPreferences
Java 对象序列化